
 This article contains an overview of shellcode development techniques and their specific aspects. Understanding these concepts allows you to write your own shellcode. Furthermore, you could modify existing exploits that contain already made shellcode to perform custom functionality that you need.
This article contains an overview of shellcode development techniques and their specific aspects. Understanding these concepts allows you to write your own shellcode. Furthermore, you could modify existing exploits that contain already made shellcode to perform custom functionality that you need.
Introduction
Let’s say you have a working exploit in Internet Explorer or Flash Player that opens calc.exe. This isn’t really useful, is it? What you really want is to execute some remote commands or to do other useful functionality.
In this situation you may want to use standard existing shellcode as the ones from Shell Storm database or generated by from Metasploit’s msfvenom tool. However, you must first understand the basic principles of shellcoding so you can use them effectively in your exploits.
For those who are not familiar with this term, as Wikipedia says:
“In computer security, a shellcode is a small piece of code used as the payload in the exploitation of a software vulnerability. It is called “shellcode” because it typically starts a command shell from which the attacker can control the compromised machine, but any piece of code that performs a similar task can be called shellcode… Shellcode is commonly written in machine code.”
A shellcode is a piece of machine code that we can use as the payload for an exploit. What is this “machine code”? Let’s take as an example the following C code:
#include <stdio.h>
int main()
{
printf("Hello, World!\n");
return 0;
}
This is translated into ASM as the following code:
_main PROC
push ebp
mov ebp, esp
push OFFSET HelloWorld ; "Hello, World!\n"
call _printf
add esp, 4
xor eax, eax
pop ebp
ret 0
_main ENDP
The important thing here is to notice that there is a main procedure and a call to a printf function.
This code is assembled into machine code, as you can see highlighted in the debugger:

So “55 8B EC 68 00 B0 33 01 … ” is the machine code for our C code.
How is the shellcode used inside an exploit?
Let’s take as an example a simple exploit, a stack based buffer overflow vulnerability.
void exploit(char *data)
{
char buffer[20]; // The buffer is on stack
strcpy(buffer, data); // Use strcpy to copy data
}
The main idea to exploit this vulnerability is the following (please note that it is not the purpose of this article to detail how buffer overflow exploits work):
- Send the application a string larger than 20 bytes which also contains your shellcode
- The stack gets corrupted by overwriting past the boundaries of the statically allocated buffer. Your shellcode will be placed on the stack
- Your string will overwrite a piece of important data on the stack (for instance the saved EIP or a function pointer) with a custom memory address
- The application will jump to your shellcode from the stack and start executing the machine code instructions inside
If you are able to successfully exploit this vulnerability you will be able to run your shellcode and you will actually do something useful with the vulnerability, not only crash the program. The shellcode could open a shell, download and execute a file, reboot the computer, enable RDP or any other action.
Shellcode specific aspects
But a shellcode is not any machine code. There are some specific aspects that we must take into account when writing our own shellcode:
- We can’t use direct offsets to strings
- We don’t know the addresses of functions (ex. printf)
- We must avoid some specific bytes (ex. NULL bytes)
Let’s have a short discussion about each of the above issues.
- Direct offsets to strings
Even if in a C/C++ code you can define a global variable, a string with the value “Hello, world!”, or you can directly place the string as a parameter to a function like in our “Hello, world” example, the compiler will place that string in a specific section of the file:
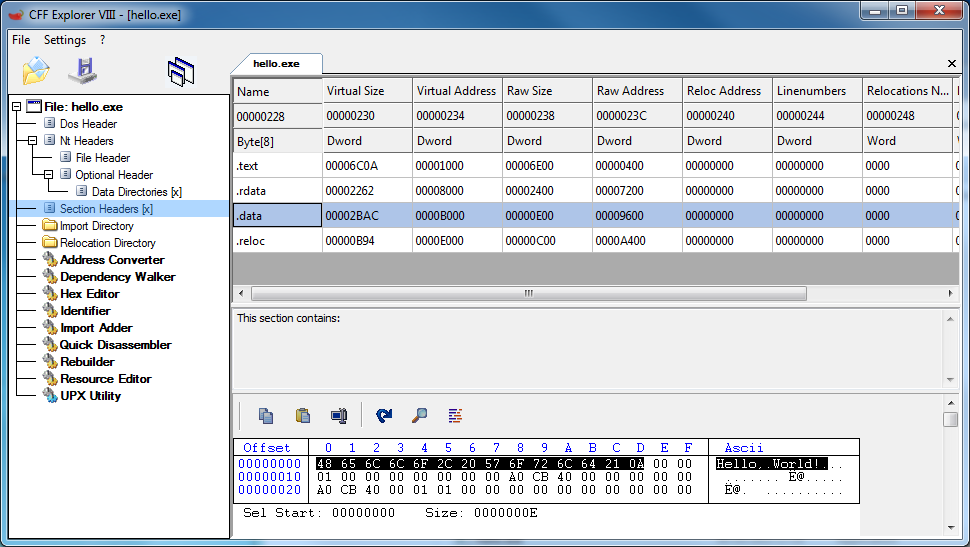
Since we need position independent code, we want to have strings as a part of our code, so must store the string on the stack as you will see in the future parts of this article.
- Addresses of functions
In C/C++ it’s easy to call a function. We specify #include <> to use a specific header and call a function by its name. In the background, the compiler and the linker takes care of the problem: they resolve the addresses of functions (for example, MessageBox from user32.dll) and we can easily call these functions by their names.

In a shellcode, we cannot do this. We don’t know if the DLL containing our required function is loaded into memory and we don’t know the address of the required function. The DLL, because of the ASLR (Address space layout randomization), will not be loaded every time at the same address. Also, the DLL may be changed with each new Windows update so we cannot rely on a specific offset in the DLL.
We must load the DLL into memory and find the required functions directly from the shellcode. Fortunately, the Windows API offers two useful functions: LoadLibrary and GetProcAddress, that we can use to find the addresses of our functions.
- Avoiding NULL bytes
The NULL bytes have the value 0x00. In C/C++ code a NULL byte is considered the terminator of a string. Because of this, the presence of these bytes in the shellcode might disturb the functionality of the target application and our shellcode might not be correctly copied into memory.
Even this situation is not mandatory, there are common cases like buffer overflows where the strcpy() function is used. This function, will copy a string byte by byte and it will stop when it will encounter a NULL byte. So if the shellcode contains a NULL byte, strcpy function will stop at that byte and the shellcode will not be complete and as you can guess, it will not work correctly.

The two instructions from the picture above are equivalent as functionality, but as you can see, the first one contains NULL bytes, while the second one does not. Even if NULL bytes are common in compiled code, it is not that difficult to avoid them.
Also, there are specific cases when the shellcode must avoid characters, such as \r or \n, or even to use only alpha-numeric characters.
Linux vs Windows shellcodes
It is simpler to write a shellcode for Linux, at least a basic one. This is because on Linux, it is possible to use system calls (system “functions”), such us write, execve or send, very easily with the 0x80 interrupt (take it as a “function call”). You can find a list of syscalls here.
As an example, a “Hello, world” shellcode on Linux requires the following steps:
- Specify syscall number (such as “write”)
- Specify syscall parameters (such as stdout, “Hello, world”, length)
- Interrupt 0x80 to execute the syscall
This will result in a call to: write(stdout, “Hello, world”, length).
On Windows this is more complicated. There are more required steps in order to create a reliable shellcode.
- Obtain the kernel32.dll base address
- Find the address of GetProcAddress function
- Use GetProcAddress to find the address of LoadLibrary function
- Use LoadLibrary to load a DLL (such as user32.dll)
- Use GetProcAddress to find the address of a function (such as MessageBox)
- Specify the function parameters
- Call the function
Conclusion
This is the first part from a series of articles on how to write a Windows shellcode for beginners. This is the introduction required in order to understand what is a shellcode, which are the limitations and which are the differences between Windows and Linux shellcode.
The second part will cover a short introduction into assembly language, the format of the PE (Portable Executable) files and the PEB (Process Environment Block). You will later see how this will help you to write a custom shellcode.

Thank you for this. I look forward to the next parts! Do you know of a good Linux shellcode development tutorial?
LikeLike
Here is a detailed whitepaper on Liux shellcodes: https://www.exploit-db.com/docs/21013.pdf
It explains a bit of everything.
However, you’ll find a lot of resources on search engines, just search for “Linux shellcode”.
If you have any question related to shellcodes,you can ask me here.
LikeLike
Thanks! I’m just starting to learn this and would like to begin with Linux.
LikeLike